上一篇《glibc-fopen源码阅读》 讲到了fopen是怎么工作的,以及FILE是怎么和文件关联起来的。但是再次阅读之后,发现还是有些细节存在疑问:
系统调用openat怎么就拿到了fd? struct file怎么和文件内容关联起来的,什么时候关联起来的?带着以上疑问,继续阅读系统的open类函数。不过仅了解fopen也是可以的,并不影响对glibc的文件打开过程的理解。
系统调用open 上篇已经说到,fopen最终通过系统调用openat拿到了文件的fd,并且将fd放到了FILE的_fileno成员中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
int
__libc_open64 ( const char * file , int oflag , ...)
{
int mode = 0 ;
if ( __OPEN_NEEDS_MODE ( oflag ))
{
va_list arg ;
va_start ( arg , oflag );
mode = va_arg ( arg , int );
va_end ( arg );
}
return SYSCALL_CANCEL ( openat , AT_FDCWD , file , oflag | EXTRA_OPEN_FLAGS ,
mode );
}
openat fopen最终走到的系统调用是openat,openat调用的是do_sys_open,对fopen来说,调用openat和open是一样的:
1
2
3
4
5
6
7
8
9
10
11
12
13
SYSCALL_DEFINE3 ( open , const char __user * , filename , int , flags , umode_t , mode )
{
if ( force_o_largefile ())
flags |= O_LARGEFILE ;
return do_sys_open ( AT_FDCWD , filename , flags , mode );
}
SYSCALL_DEFINE4 ( openat , int , dfd , const char __user * , filename , int , flags ,
umode_t , mode )
{
if ( force_o_largefile ())
flags |= O_LARGEFILE ;
return do_sys_open ( dfd , filename , flags , mode );
}
open和openat指向的都是do_sys_open这个函数,下面来看do_sys_open:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
long do_sys_open ( int dfd , const char __user * filename , int flags , umode_t mode )
{
struct open_flags op ;
int fd = build_open_flags ( flags , mode , & op );
struct filename * tmp ;
if ( fd )
return fd ;
tmp = getname ( filename );
if ( IS_ERR ( tmp ))
return PTR_ERR ( tmp );
fd = get_unused_fd_flags ( flags );
if ( fd >= 0 ) {
struct file * f = do_filp_open ( dfd , tmp , & op );
if ( IS_ERR ( f )) {
put_unused_fd ( fd );
fd = PTR_ERR ( f );
} else {
fsnotify_open ( f );
fd_install ( fd , f );
}
}
putname ( tmp );
return fd ;
}
初看可以分为几个部分:
建立open flag 获取name(什么name?) 获取fd 打开文件 通知file system 将文件注册到进程 下面逐个分析。
build_open_flags 先是根据不同情况设置不同的open flag,我认为这里不是重点,稍微看看就好了,不过注意一下O_TMPFILE_MASK(因为最近用到了tmpfile这个函数…),有些情况是会直接返回一个错误码的。所以,fd相关的返回值,如果是负数则表示发生错误,可以从其返回值大致判断错误类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
static inline int build_open_flags ( int flags , umode_t mode , struct open_flags * op )
{
// ......
if ( flags & __O_TMPFILE ) {
if (( flags & O_TMPFILE_MASK ) != O_TMPFILE )
return - EINVAL ;
if ( ! ( acc_mode & MAY_WRITE ))
return - EINVAL ;
} else if ( flags & O_PATH ) {
/*
* If we have O_PATH in the open flag. Then we
* cannot have anything other than the below set of flags
*/
flags &= O_DIRECTORY | O_NOFOLLOW | O_PATH ;
acc_mode = 0 ;
}
// ......
return 0 ;
}
getname getname会返回一个filename的结构体,所以先来看看filename结构体:
1
2
3
4
5
6
7
struct filename {
const char * name ; /* pointer to actual string */
const __user char * uptr ; /* original userland pointer */
int refcnt ;
struct audit_names * aname ;
const char iname [];
};
audit对应的是linux审计系统相关,就先不理它了。其余注意到filename结构体主要是存储了一些字符串,大概可以猜想到是存储的文件路径相关的字符串。但是为什么需要这么多成员来存储呢?
再看getname函数指向的getname_flags,这里或许可以找到filename的一些原理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
struct filename *
getname_flags ( const char __user * filename , int flags , int * empty )
{
//......
const size_t size = offsetof ( struct filename , iname [ 1 ]);
kname = ( char * ) result ;
/*
* size is chosen that way we to guarantee that
* result->iname[0] is within the same object and that
* kname can't be equal to result->iname, no matter what.
*/
result = kzalloc ( size , GFP_KERNEL );
if ( unlikely ( ! result )) {
__putname ( kname );
return ERR_PTR ( - ENOMEM );
}
result -> name = kname ;
len = strncpy_from_user ( kname , filename , PATH_MAX );
//.......
result -> refcnt = 1 ;
//......
result -> uptr = filename ;
result -> aname = NULL ;
audit_getname ( result );
return result ;
}
kname指向的是filename结构体的第一个成员,它会alloc一段空间,下面是关于kzalloc函数的描述:
1
2
3
4
5
6
7
8
9
10
/*
* kmalloc is the normal method of allocating memory
* for objects smaller than page size in the kernel.
*/
static __always_inline void * kmalloc ( size_t size , gfp_t flags );
static inline void * kzalloc ( size_t size , gfp_t flags )
{
return kmalloc ( size , flags | __GFP_ZERO );
}
现在可以知道,filename结构体的name成员指向了kmalloc申请的一块内存,这块内存的最大空间是1Page,这也就是为什么会有PATH_MAX这个系统宏了,其对应大小是4096,在我的系统上就是一个Page的大小。
1
2
3
len = strncpy_from_user ( kname , filename , PATH_MAX );
result -> refcnt = 1 ;
result -> uptr = filename ;
以上,filename结构体的name成员指向了自己分配的一块内存,其内容是filename这个字符串的拷贝,uptr成员则指向了filename这个字符串,refcnt成员被置为1。但是,现在还没回答上面的问题,为什么filename结构体会有两个成员来存储同一个字符串?
可以大概猜想一下,调用完open之后,filename字符串因为是用户申请的,所以可能被回收,如果后续还在使用的话就存在越界的可能,所以需要一块额外的空间存储filename字符串,所以就自己申请一块了。后续还会用到filename结构体的name成员。
get_unused_fd_flags get_unused_fd_flags调用的是__alloc_fd函数,这里注意到current,先前已经介绍过,代表当前的task_struct,所以这里拿到了当前进程的files,在《进程控制和通信(四) · PCB介绍 》 中已经讲过task_struct和files的关系了。
1
2
3
4
int get_unused_fd_flags ( unsigned flags )
{
return __alloc_fd ( current -> files , 0 , rlimit ( RLIMIT_NOFILE ), flags );
}
下面是摘取自__alloc_fd的一些语句:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
fdt = files_fdtable ( files );
fd = start ;
if ( fd < files -> next_fd )
fd = files -> next_fd ;
if ( fd < fdt -> max_fds )
fd = find_next_fd ( fdt , fd );
//......
error = expand_files ( files , fd );
/*
* If we needed to expand the fs array we
* might have blocked - try again.
*/
if ( error )
goto repeat ;
if ( start <= files -> next_fd )
files -> next_fd = fd + 1 ;
__set_open_fd ( fd , fdt );
// ......
可以知道,__alloc_fd的大致过程:
获取fdtable 找到一个可用的fd 如果没有可用的fd,则尝试扩展fdtable(参考《进程控制和通信(四) · PCB介绍 》 ) 扩展后在尝试找一个可用的fd 找fd成功,设置fdtable对应bit位 目前为止,文件还是没有被打开,也没有对filename指向的文件做任何操作。不过,fd和filename结构体准备好后,就可以打开文件了。
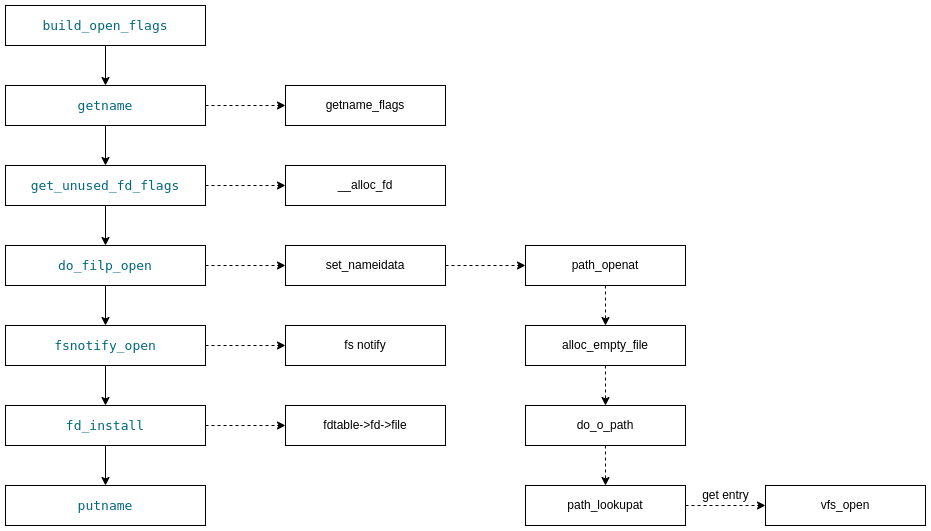
do_filp_open 以下是do_filp_open函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
struct file * do_filp_open ( int dfd , struct filename * pathname ,
const struct open_flags * op )
{
struct nameidata nd ;
int flags = op -> lookup_flags ;
struct file * filp ;
set_nameidata ( & nd , dfd , pathname );
filp = path_openat ( & nd , op , flags | LOOKUP_RCU );
if ( unlikely ( filp == ERR_PTR ( - ECHILD )))
filp = path_openat ( & nd , op , flags );
if ( unlikely ( filp == ERR_PTR ( - ESTALE )))
filp = path_openat ( & nd , op , flags | LOOKUP_REVAL );
restore_nameidata ();
return filp ;
}
这个函数看着比较简单,大概是先通过filename得到一个nameidata的结构体,然后就用这个nameidata生成了一个struct file。
nameidata是什么?还是先来看看这个结构体的成员:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
struct nameidata {
struct path path ;
struct qstr last ;
struct path root ;
struct inode * inode ; /* path.dentry.d_inode */
unsigned int flags ;
unsigned seq , m_seq ;
int last_type ;
unsigned depth ;
int total_link_count ;
struct saved {
struct path link ;
struct delayed_call done ;
const char * name ;
unsigned seq ;
} * stack , internal [ EMBEDDED_LEVELS ];
struct filename * name ;
struct nameidata * saved ;
struct inode * link_inode ;
unsigned root_seq ;
int dfd ;
} __randomize_layout ;
我认为重要的就是两个inode,一个是dentry的inode,一个是link_inode。
set_nameidata只是大概填写nameidata的一些基础信息,关于inode的部分这里并没有填写。
1
2
3
4
5
6
7
8
9
10
static void set_nameidata ( struct nameidata * p , int dfd , struct filename * name )
{
struct nameidata * old = current -> nameidata ;
p -> stack = p -> internal ;
p -> dfd = dfd ;
p -> name = name ;
p -> total_link_count = old ? old -> total_link_count : 0 ;
p -> saved = old ;
current -> nameidata = p ;
}
所以,接下来需要关注path_openat函数是怎么填写nameidata的:
1
2
file = alloc_empty_file ( op -> open_flag , current_cred ());
error = do_o_path ( nd , flags , file );
摘取了一些语句,大致过程如上,先是申请了一个空的struct file,根据alloc_empty_file的输入参数,也大概可以看出,alloc_empty_file只是申请了一个结构体之类的内存,不会真正打开文件(因为没有路径等信息输入)。然后是do_o_path(这里有多个类似的函数入口,仅挑选do_o_path追踪):
1
2
3
4
5
6
7
8
9
10
11
static int do_o_path ( struct nameidata * nd , unsigned flags , struct file * file )
{
struct path path ;
int error = path_lookupat ( nd , flags , & path );
if ( ! error ) {
audit_inode ( nd -> name , path . dentry , 0 );
error = vfs_open ( & path , file );
path_put ( & path );
}
return error ;
}
大概是两步:
1
2
int error = path_lookupat ( nd , flags , & path );
error = vfs_open ( & path , file );
在path_lookupat的时候会填写nameidata的inode等成员,因此,path_lookupat之后可以通过nameidata拿到文件的dentry信息了,在dentry的inode表里就可以找到文件对应的inode。
然后通过vfs_open打开文件,拿到文件的inode等信息填写到struct file结构体中。不同的vfs会有对应的open方法,vfs_open指向的do_dentry_open方法中,就会使用文件所在vfs的open方法来打开文件。
到目前为止,已经打开文件,拿到文件的inode等信息,并且写入struct file了。
do_filp_open过程
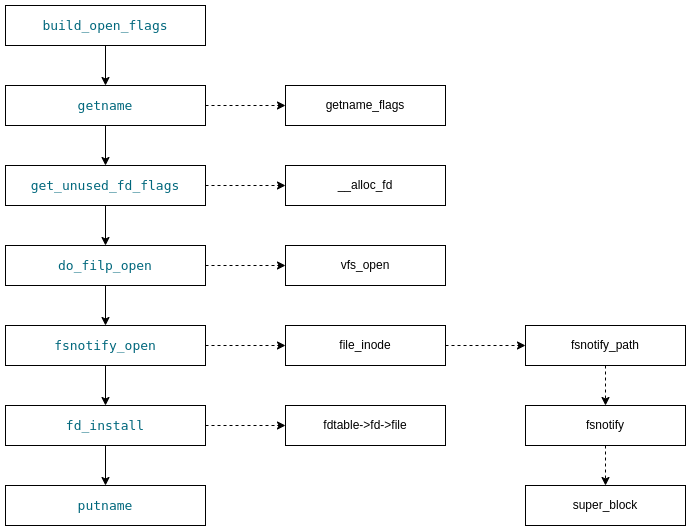
fsnotify_open 略。(这部分有机会单独讲,关于Linux文件事件)
fsnotify_open过程
fd_install 文件已经打开了,怎么让进程拥有这个文件呢?并且我们已经知道,文件可以通过一个fd就能打开了。关键是fd_install函数:
1
2
3
4
void fd_install ( unsigned int fd , struct file * file )
{
__fd_install ( current -> files , fd , file );
}
通过current可以获得当前task_struct的files_struct,进而可以获得fdtable。然后将fdtable的第fd个元素指向file这个struct file结构体。此时通过task_struct就可以找到对应的文件了,并且通过fd就能准确在fdtable中找到对应的struct file。